






The Complete Guide
What is Data Fabric?
Last updated on May 15, 2024

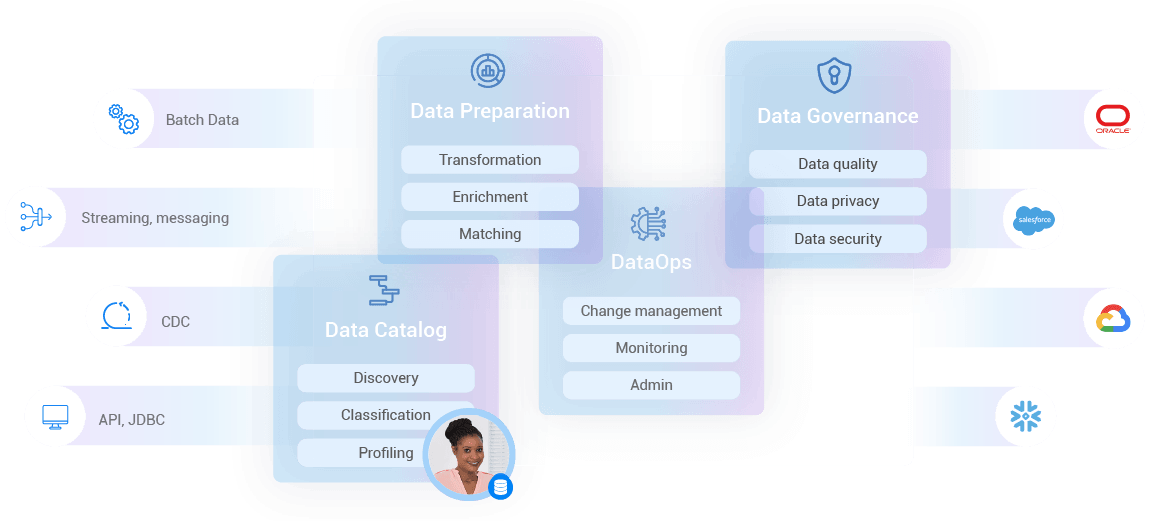

 Table of Contents
Table of Contents
Data fabric is a centralized data architecture that serves authorized consumers with integrated, governed, fresh data – for analytical and operational workloads.
Over the past few years, the term “data fabric” has become synonymous with enterprise data integration and management. Analyst firm Gartner estimates that a data fabric reduces the time for data integration design by 30%, deployment by 30%, and maintenance by 70%.

03
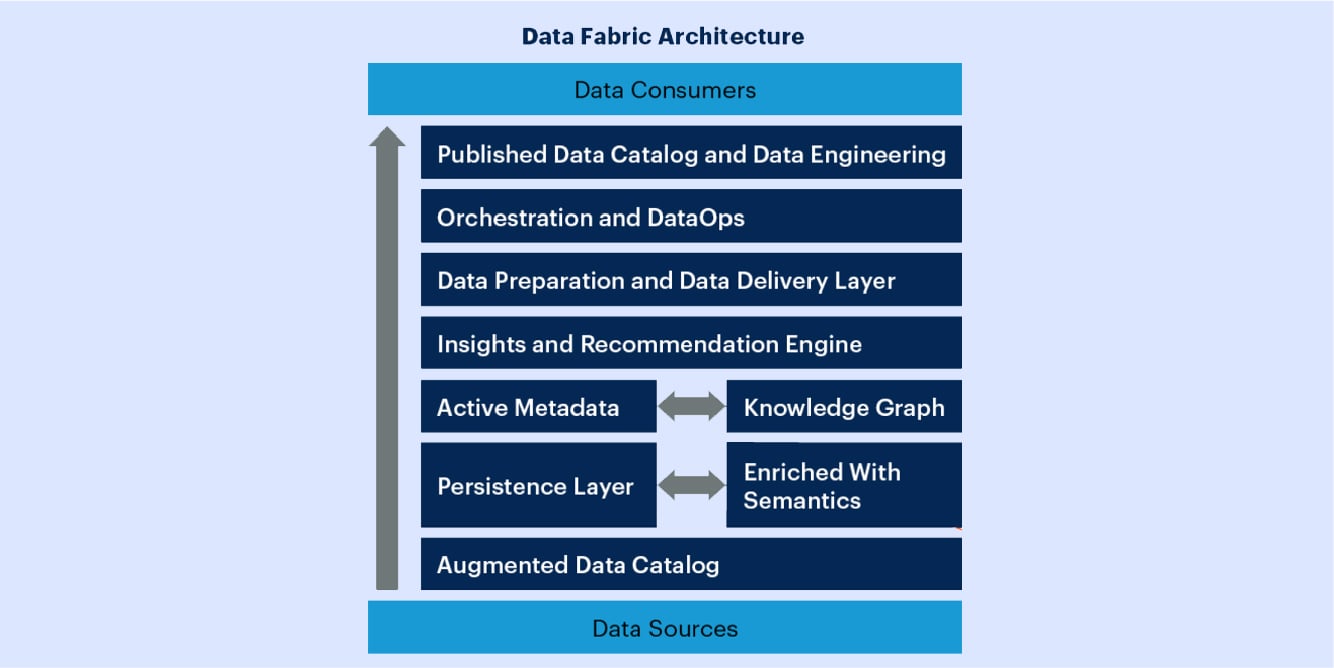
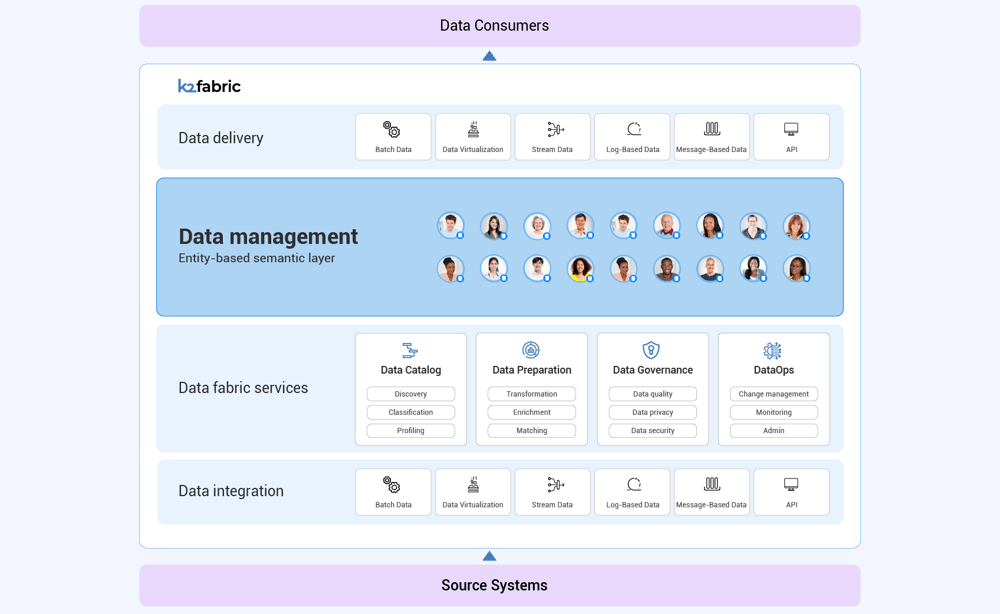
Data Fabric Architecture
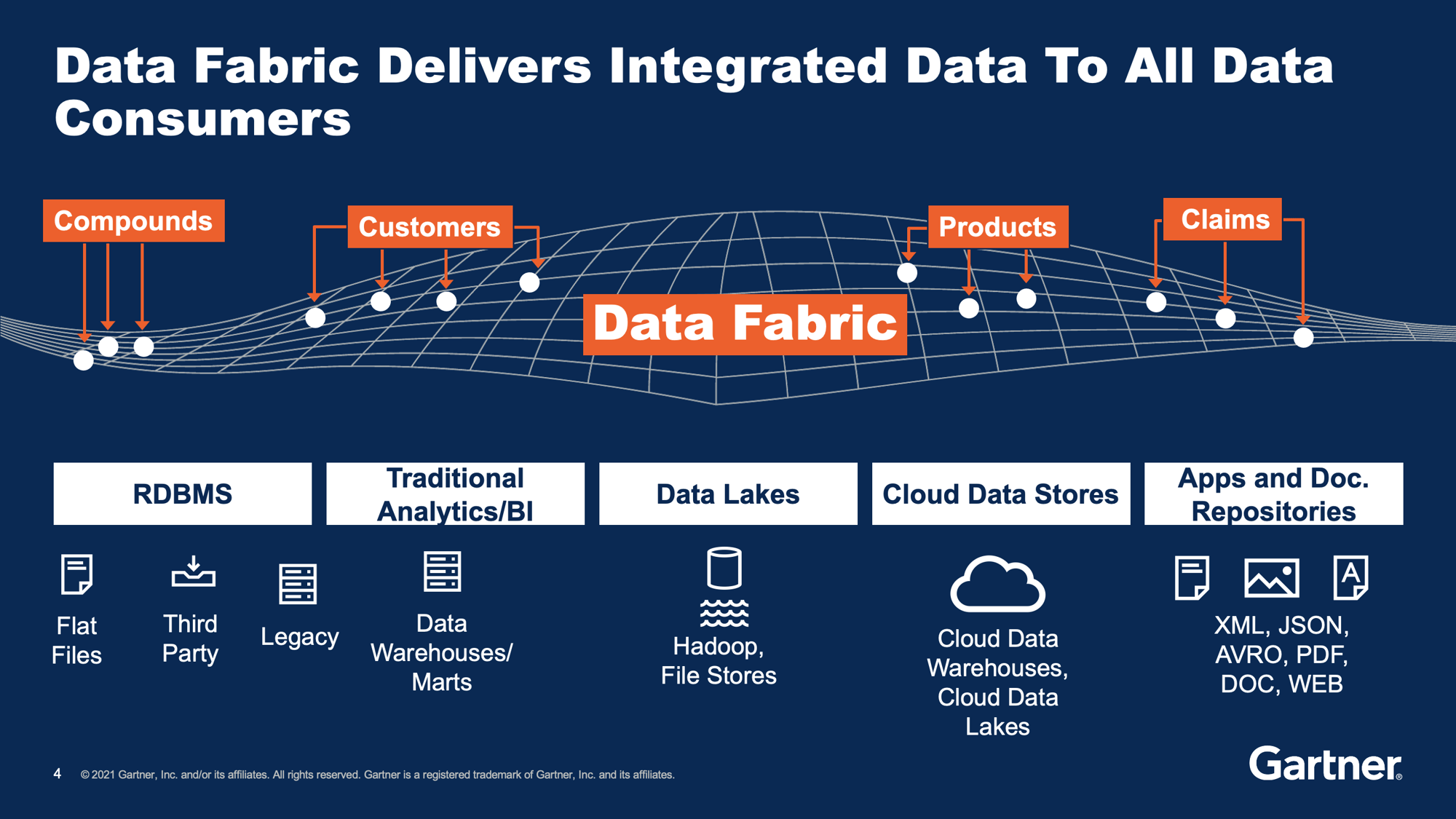
Gartner: An ideal, complete data fabric design with its many components.
A well designed data fabric architecture is modular and supports massive scale, distributed multi-cloud, on-premise, and hybrid deployment.
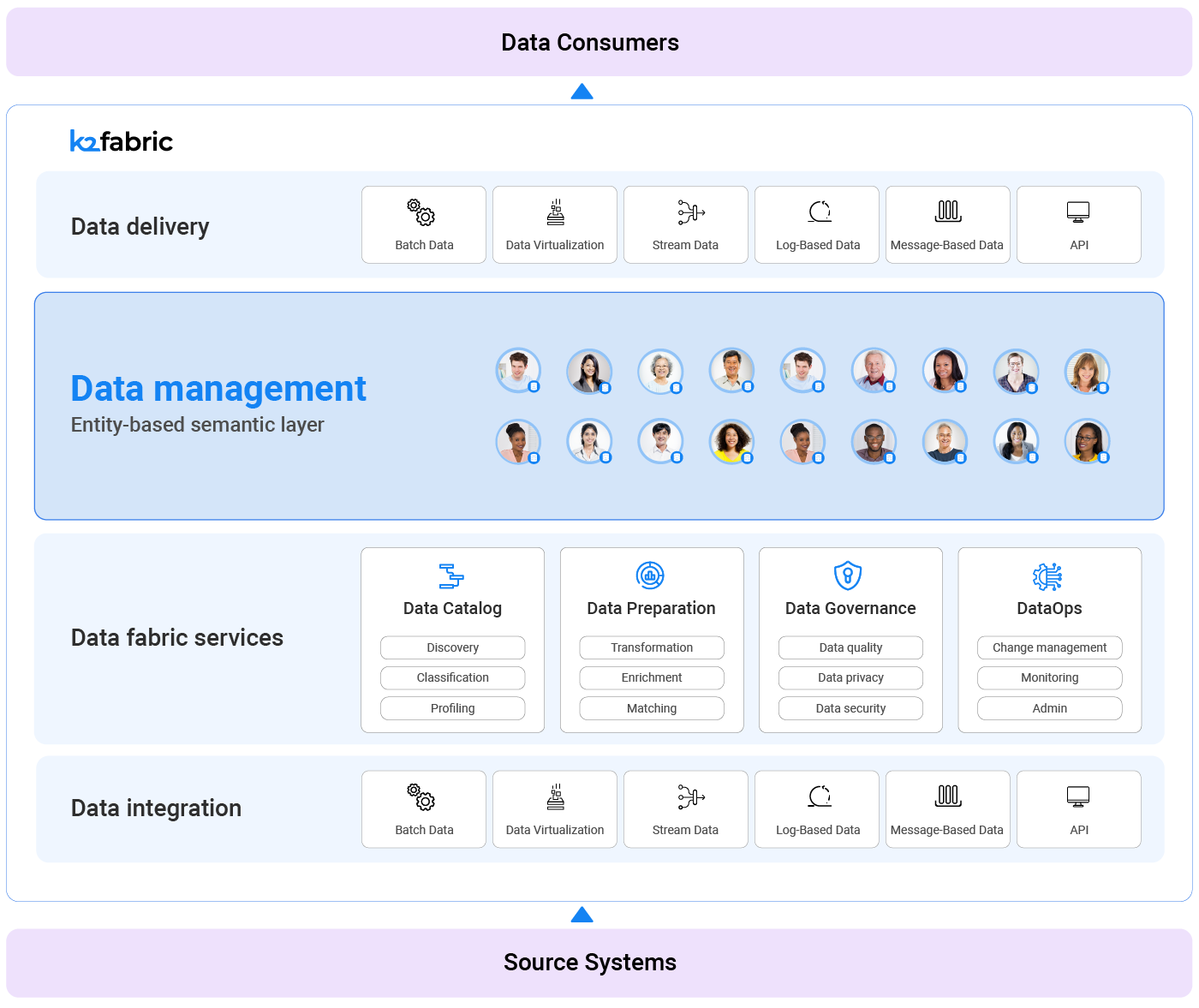
As the diagram above illustrates, as data is provisioned from sources to consumers, it is cataloged, prepared, enriched to provide insights and recommendations, orchestrated, and delivered.
The data fabric is able to integrate and unify data from all data sources, ranging from siloed legacy systems to modern cloud applications and analytical datastores (data warehouses and lakes).
Data consumers of the data fabric include analytical data users such as data scientists and data analysts, as well as operational workloads such as MDM, Customer 360, test data management, and more.



10
Data Fabric Vendors
There are multiple vendors that deliver an integrated set of capabilities to support the data fabric architecture. The top 5 data fabric vendors appear below:
|
Strengths |
Concerns |
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|






