











Generative AI hallucinations are incorrect or nonsensical GenAI outputs, resulting from flawed data or misinterpretations of data patterns during training.
Causes and consequences of GenAI hallucinations
What is grounding and hallucinations in AI? In humans, a hallucination is a perceptual experience that seems real but isn't – seeing, hearing, smelling, tasting, or feelings things that just aren't there. In a similar sense, an AI hallucination is an untrue or whimsical output based on bad data.
What causes generative AI hallucinations? 2 main factors:
-
The quality of the training data
If the data used to train a GenAI system is flawed or incomplete, the system will reflect those flaws in its outputs. Consider a historical archive filled with factual errors. A generative AI model trained on this data could easily report incorrect information.
-
The way AI learns
GenAI models “learn” by identifying patterns in training data and extrapolating responses based on these patterns. But patterns can often be misleading, which causes the model to “overfit” the data. Overfitting is when Large Language Models (LLMs) – like ChatGPT by OpenAI or LLaMA by Meta AI – focus too narrowly on the specific details of the training data and have a hard time handling new information and adapting to new situations.
The consequences of hallucinations can range from minor inconveniences to serious infractions. While historical inconsistencies could be amusing, a medical AI system that misdiagnoses a patient based on a faulty perception of data could have life and death implications.
Despite the prevalence of AI in life and business, generative AI hallucinations are far more common than you’d expect. According to a recent survey, a leading LLM hallucinates more than 20% of the time, while the more mainstream LLMs ‘only’ hallucinate 3-5% of the time.
A great way to reduce generative AI hallucinations is via LLM grounding. Company LLMs can be infused with structured and unstructured enterprise data in real time with Retrieval-Augmented Generation (RAG), a generative AI framework designed to deliver more accurate and personalized responses.
Spotting generative AI hallucinations
An LLM is a powerful tool, but like any tool, it has its limitations. Here’s how to identify generative AI hallucinations, which can be deceptively believable. Look out for:
-
Off-track betting
A valid response should be a logical answer to a specific question, and not a best bet. So, look for inconsistencies. Does the AI response introduce irrelevant points or deviate from the topic? Does it contradict established facts or details mentioned earlier? If the answer is “Yes”, you might be looking at a fabrication.
-
Hocus-pocus
Trained on huge datasets, an LLM uses statistical probabilities to formulate its responses – often leading to answers that are technically possible but highly improbable. For example, an LLM might write a historical biography that includes awards the subject of the biography never received – awards which might fit in well with the story but are simply made up.
-
Sentimental journeys
Responses that try to evoke an emotional response are red flags. While an LLM is trained to mimic human emotions, it can’t grasp the contextual subtleties of emotional context. A highly sentimental story, or a strangely dramatic twist of events, could be warning signs of a made-up response.
-
The small print
When stating facts, a reliable generative AI model should be able to back them up. A legitimate response about historical events, scientific discoveries, or specific data points should reference credible sources. An LLM that makes a claim without referencing it could be hallucinating.
-
Trivial pursuits
Pay close attention to the content of the response, even if it appears to flawlessly mimic human speech patterns. Does the answer include overly specific or technical details that seem out of place? Including extraneous details or unnecessarily specific descriptions could be a sign of hallucinations.
Preventing generative AI hallucinations
Here's how data teams are using AI data to prevent generative AI hallucinations:
-
Data preparation
Since the information an LLM learns from is crucial, researchers prioritize data that's accurate and unbiased. To do so, they cleanse the data to eliminate errors and bias to provide the LLM with a more balanced and truthful perspective.
-
Data augmentation
Even the best data may have gaps, so a good fact-checking mechanism – like retrieval-augmented generation vs fine-tuning – is critical. As the LLM generates text, these mechanisms compare its output with established knowledge sources like scientific journals, news articles, or internal knowledge bases. For example, a customer-facing RAG chatbot would leverage user details like pricing and past service history.
-
Data validation
Beyond data preparation and augmentation, researchers are also focusing on improving LLM reasoning abilities. While current models excel at recognizing patterns and analyzing statistics, better reasoning would allow them to assess the credibility of their responses. For instance, a mobile phone provider's chatbot offering personalized recommendations might use enhanced reasoning to identify illogical suggestions, like a single user subscribing to multiple plans at the same time.
-
Data transparency
Techniques are being developed to reveal the sources LLMs reference when generating responses. Knowing these sources allows users to evaluate the information's trustworthiness and identify potential biases in the training data. This transparency empowers users to critically analyze the information and understand the thought process of the model.
-
Data trust
Active Retrieval-Augmented Generation (ARAG) strengthens the factual basis of generative AI outputs by injecting LLMs with data from private enterprise sources. ARAG utilizes an organization's internal systems to identify relevant information that complements the LLM's knowledge base. This functionality allows the LLM to anchor its responses in trusted data, minimizing the risk of spurious or silly responses.
Avoiding hallucinations with GenAI Data Fusion
The proven path to preventing generative AI hallucinations is to use an advanced RAG tool that accesses and augments both structured and unstructured data from private company sources. This approach, called GenAI Data Fusion, consolidates all structured data belonging to a single business entity (customer, employee, invoice, etc.) using a data-as-a-product approach.
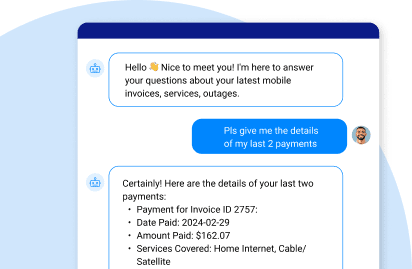
Data products enable GenAI Data Fusion to access real-time data from multiple enterprise systems, not just static docs from knowledge bases. With this feature, LLMs can leverage RAG to integrate data from your customer 360 platform, and turn it into contextual prompts. The prompts are fed into the LLM together with the user’s query, enabling the LLM to generate a more accurate and personalized response.
K2View’s data product platform lets RAG access data products via API, CDC, messaging, or streaming – in any variation – to unify data from many different source systems. A data product approach can be applied to various RAG use cases to:
-
Fix problems quicker.
-
Build hyper-personalized marketing campaigns.
-
Personalize up-/cross-sell insights and recommendations.
-
Detect fraud via suspicious activity in user accounts.
Preempt generative AI hallucinations with the marketing-leading RAG tool – GenAI Data Fusion by K2view.




