






A practical guide to Table-Augmented Generation (TAG)
What is Table Augmented Generation (TAG)?
Updated April 1, 2025


 Table of Contents
Table of Contents
04
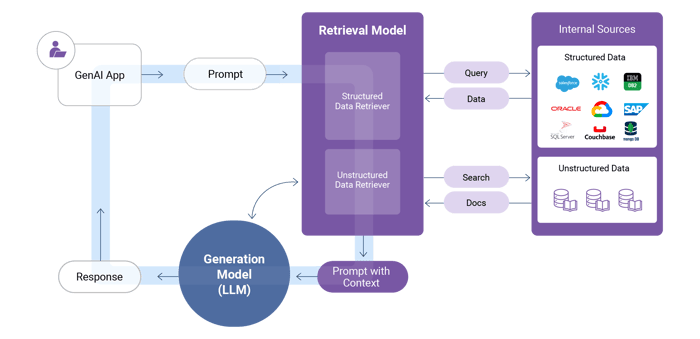
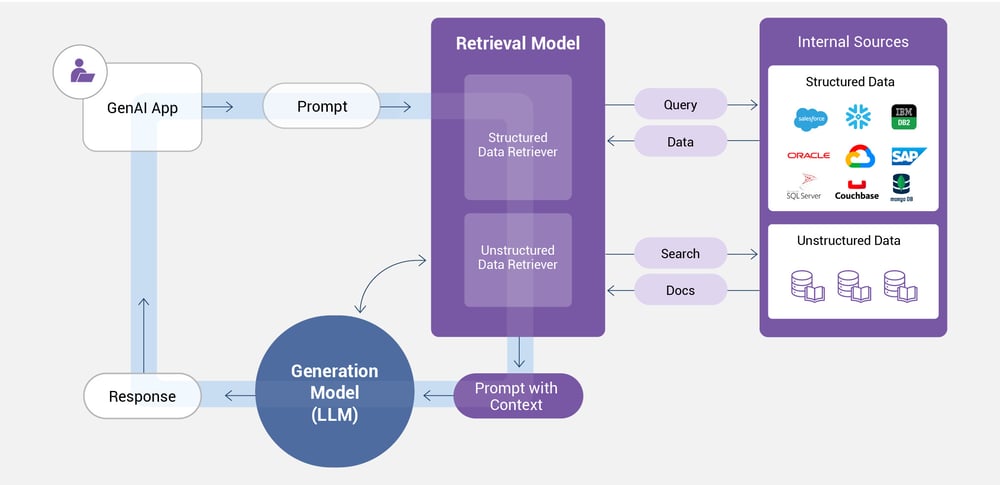
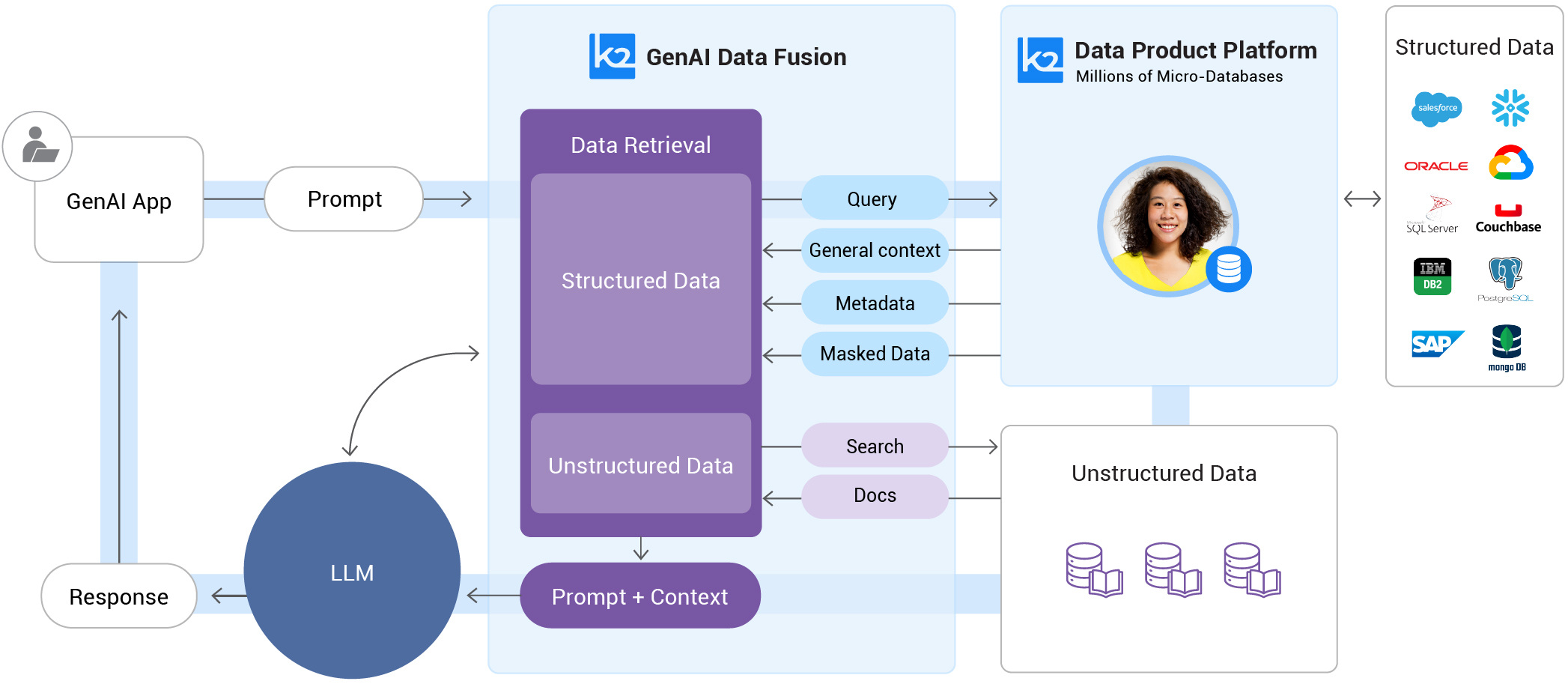
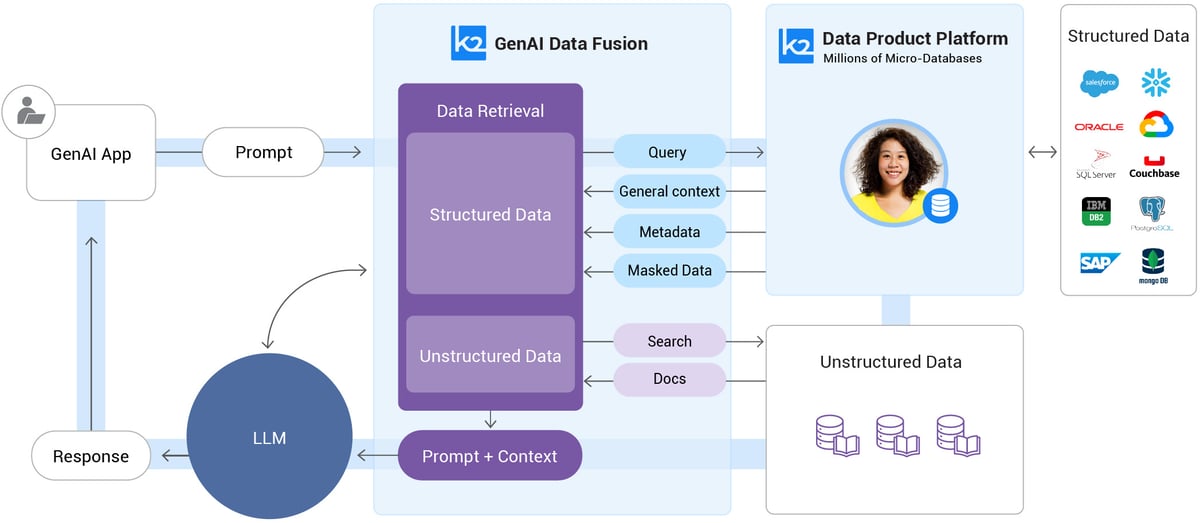
Table-augmented generation challenges
Producing precise, dependable, and relevant responses is crucial.
However, TAG also presents certain challenges:
- Enterprise TAG depends on data retrieval across the entire organization. It's essential not only to maintain current and accurate data but also to have precise metadata that accurately describes your data for the TAG framework.
- The data stored in your enterprise systems must meet the data quality for AI standards of compliance, completeness, and freshness. For instance, if you manage 100 million customer records, can you retrieve and integrate all the data relevant to David Smith in under a second?
- Generating insightful contextual prompts requires advanced AI prompt engineering skills, such as chain-of-thought reasoning, to effectively inject the relevant data into the LLM in a manner that yields the most accurate responses.
- To safeguard data privacy and security, LLM access must be restricted to authorized data only. Using the prior example, this means providing access solely to David Smith's data and to no one else's.
In addition to these challenges, organizations have expressed further concerns, as highlighted in our recent survey below:

Top concerns in leveraging enterprise data for GenAI and RAG
Source: K2view Enterprise Data Readiness for GenAI in 2024 report
Given the equal distribution of key concerns, it's clear that focusing solely on one of them – such as scalability and performance, while neglecting data quality and consistency, real-time data integration and access, data governance and compliance, or data security and privacy – will not suffice. To effectively combine enterprise data with GenAI initiatives, a comprehensive, integrated strategy is needed.
"Organizations are continuing to make significant investments in GenAI," says the 2024 Gartner LLM report, Lessons from Generative AI Early Adopters. "But they encounter difficulties related to technical implementation, expenses, and talent acquisition."
Despite these challenges and concerns, TAG represents a significant advancement in GenAI technology. Its capacity to leverage fresh enterprise data addresses the limitations of traditional generative models by enhancing user interactions with more personalized and dependable responses.
TAG is already proving its worth in various use cases, including customer service and support, IT service management, sales and marketing, and legal and compliance. But the optimal GenAI approach – whether TAG or prompt engineering vs fine-tuning – must be assessed based on the use case at hand.






-1.png?width=501&height=273&name=GenAI%20survey%20news%20thumbnail%20(1)-1.png)



