







Ground GenAI apps
with enterprise data

LLMs don’t know your business
LLMs provide generic responses – they don’t know your customers, services, employees, and suppliers.
Most of the answers lie in your app data
The data in your business systems, like CRM, ERP, and Billing, is key to answering enterprise GenAI questions.
LLMs can generate false information
Without access to your business data, LLMs may hallucinate and damage your reputation and customer trust.




- 01 No-code agent builder
- 02 Chain-of-thought orchestration
- 03 Text-to-SQL automation
- 04 Real-time data retrieval
- 05 100s of prebuilt functions
01No-code agent builder
Build your AI data agents in minutes using our no-code Studio, which includes a built-in testing and debug tool.

02Chain-of-thought orchestration
Orchestrate chain-of-thought prompting and LLM reflection to maximize LLM response accuracy.

03Text-to-SQL automation
Dynamically transform any user prompt into SQL queries that retrieve the needed enterprise data for LLM augmentation.

04Real-time data retrieval
Retrieve fresh and compliant data from the Micro-Database, at conversational latency, and within required guardrails.

05100s of prebuilt functions
Pick and config the LLM functions your data agent will use. From basic API calls and data transformations, to sophisticated data parsing and analysis – we've got you covered.

Data guardrails
Conversational latency
Responding to user prompts in millisecs to support operational GenAI use cases.
Trusted data
Controlled AI costs
AI scale
Reliable LLM responses


K2view GenAI Data Fusion enables Pelephone to slash customer service costs and elevate the customer experience
-Mar-12-2025-05-23-02-2395-PM.png?width=610&height=580&name=image%20(5)-Mar-12-2025-05-23-02-2395-PM.png)
"For a GenAI-powered chatbot to be smart and effective, a GenAI-ready data infrastructure is required. That’s where K2view enters the picture. With K2view we can safely ground our GenAI apps with customers’ data to anticipate and prioritize the reasons for a call."


Telco | Customer service chatbot
RAG can elevate your users' chatbot experiences with personalized answers, and reduce your costs with higher first contact resolution rates.
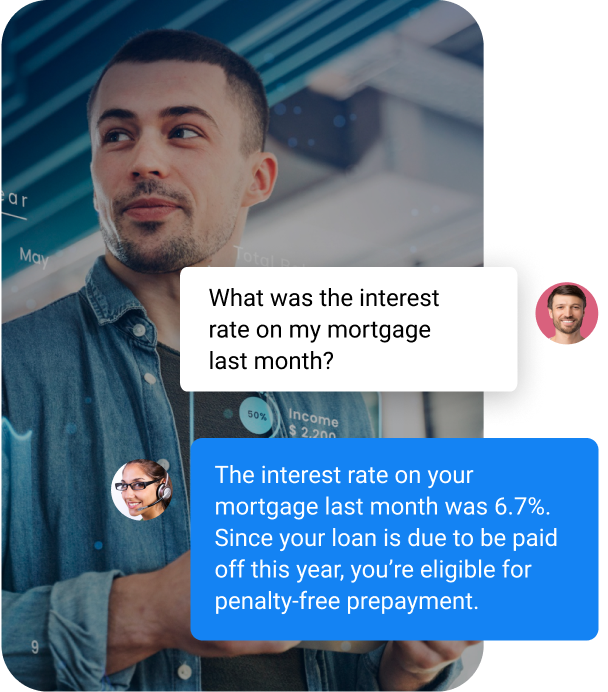
Banking | Call center assistance
RAG can provide your call center reps with 360° customer views and real-time insights, for greater customer satisfaction and reduced call times.
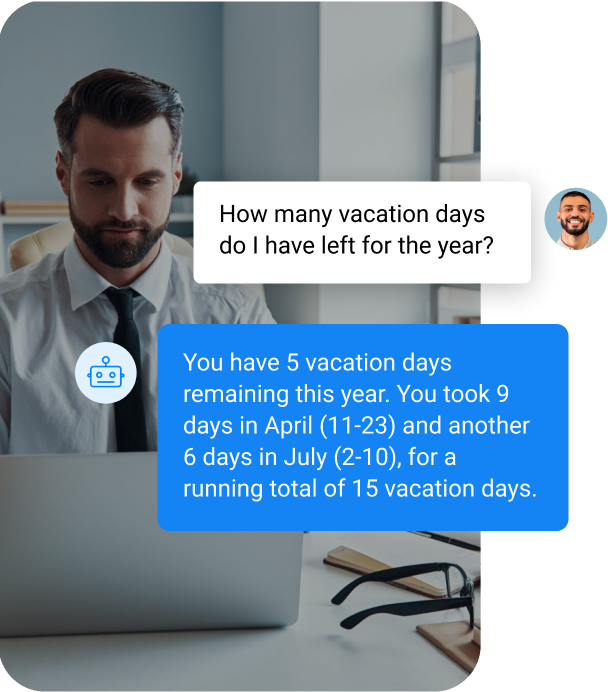
Enterprise | Internal HR applications
RAG can inject employee data into your HR app to provide users with individually tailored responses about attendance, benefits, and vacation time.
.png?width=841&height=613&name=GenAI%20survey%20(3).png "GenAI survey (3)")







-1.png?width=501&height=273&name=GenAI%20survey%20news%20thumbnail%20(1)-1.png)












