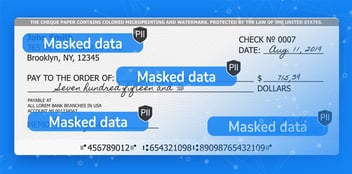
Pseudonymization substitutes codes for personally identifiable information in a dataset, while maintaining data functionality for analytics and operations.
What is Pseudonymization?
Data pseudonymization is a form of data anonymization in which identifying information in a dataset is replaced with codes, or pseudonyms. Pseudonymization makes it very difficult to attribute personal data to a specific person or event, while maintaining the ability to analyze and operationalize the data. Other forms of data anonymization include data masking, tokenization, and synthetic data generation.
With the ability to pseudonymize Personal Identifiable Information (PII), organizations can reduce privacy risks associated with handling personal data by preventing unauthorized individuals from accessing – and potentially, misusing – the data.
In this article, we’ll cover how data pseudonymization can be used to safeguard sensitive information, discuss its main advantages and drawbacks, and explain how a business entity approach to data anonymization tools provides enterprises heightened security.
Data Pseudonymization Use Cases
Pseudonymization can be used to conceal PII, such as names, dates of birth, addresses, Social Security Numbers, and other identifiers, in a variety of contexts and verticals, including healthcare, finance, and telecom. Here are some of the most common use cases for pseudonymization in enterprises:
-
Compliance with data privacy regulations
Many data privacy regulations, such as GDPR, HIPAA, CCPA, and more require companies to use anonymized data to protect individual privacy. Pseudonymization is an effective way to ensure consumer/patient anonymity and avoid the costly penalties and litigation fees that arise from noncompliance. -
Test data management
Application testing teams require realistic, complete, clean, compliant, and reliable data for test data management. By first pseudonymizing sensitive data, testing teams can use test data management tools, without exposing sensitive production data to security risk. -
Customer 360
Data pseudonymization helps organizations achieve customer 360 (also called a single customer view) without compromising customer security. A 360-degree view of the customer integrates the interaction, transaction, and master data for each customer. Not all users need access to sensitive customer data. When identifying data is pseudonymized, business users can access customer information on-demand, while keeping that data compliant and secure. -
Fraud detection and prevention
Fraud detection and prevention systems use sensitive data (such as financial information, customer data, or medical records) to detect patterns and anomalies that could signal fraudulent activity. Like data masking tools, data pseudonymization tools help protect the sensitive data these systems rely on from potential hackers, thus reducing the likelihood of a breach.
Top Advantages of Pseudonymization
Enterprises that use pseudonymization to conceal and protect sensitive information can reap many benefits, such as:
-
Preserved data functionality
Data that undergoes pseudonymization can maintain important functionality, even in its de-identified state. For example, it can still provide useful analytics, support agile software development, enable real-time testing, and equip business users with insights and information required to make better decisions. -
Enhanced data privacy
When data is pseudonymized, the original data is retained in a reference table under the organization’s control. So, datasets containing pseudonymized data are less vulnerable to a data breach – because if an attacker gains access to the dataset, they can’t trace any pseudonymized PII to an individual without having the reference data. -
Greater customer trust
As data privacy laws proliferate and expand, consumers have become more aware of their rights, as well as the implications of a data breach that exposes their personal information. Today, consumers want to know that the organizations that process or store their data are taking appropriate measures to keep that data secure. To that end, data pseudonymization helps organizations prove to customers that they are protecting their PII. -
Enhanced 3rd-party data sharing
Pseudonymization makes it easier to share data with 3rd parties securely, without revealing the identities of the individuals associated with the data. With data pseudonymization, organizations can work with 3rd-party vendors, applications, partners, and service providers while minimizing risk exposure.
4 Challenges of Pseudonymization
Along with its benefits, data pseudonymization also creates certain challenges. Here’s an overview of possible pseudonymization drawbacks:
-
Risk of re-identification
Pseudonymization is not foolproof. Malicious actors can potentially re-identify individuals if they gain access to the right information, such as the pseudonymization algorithm or reference table. The challenge is finding the right balance between preserving data utility and protecting privacy. -
Vulnerable data quality and data consistency
Pseudonymization can lead to diminished data quality and data consistency after the original data is modified, depending on how data is pseudonymized, and what it will be used for. For example, if you replace real customer addresses with fictitious ones, and then analyze where your customers live, the outcomes of this analysis could be compromised – especially if the pseudonymized addresses are very different than the original ones. -
Challenges with data linkage
Once data is pseudonymized, it can be difficult to link data across different data sources. This can limit the data’s usefulness for research and analysis as a result. -
Complex implementation
Pseudonymization can be complex to implement and maintain, especially for large datasets. It requires a significant investment of time, effort, and resources to develop effective pseudonymization techniques and ensure compliance with privacy regulations.
Why Take a Business Entity Approach to Pseudonymization
The entity-based data masking technology allows enterprises to reap the security, efficiency, and compliance-enhancing benefits of pseudonymization, without the challenges it typically creates.
A business entity approach integrates and organizes fragmented data from multiple source systems according to data schemas, in which each schema corresponds to a business entity (such as a customer, supplier, or order). This allows data teams to pseudonymize data quickly, efficiently, and reliably, ensure data functionality for a variety of use cases, and retain relational integrity across the organization.
Entity-based data pseudonymization manages all the data associated with a given entity (say, a single customer), in an encrypted Micro-Database™, which is either stored, or cached in memory. This novel, patented technology enables rapid data pseudonymization that maintains the highest security standard, simplifies compliance, and equips business users with secure, functional data insights.