








What are the challenges and benefits of building data pipelines? This article examines all the requirements, and a data product approach that has them all.
Table of Contents
Data Pipeline Defined
Clean Data Wanted
Automation Needed
Data Pipeline Challenges
Finding the Right Data Pipeline Solution
Data Pipeline Defined
Generally speaking, an enterprise data pipeline includes a broad array of data-related tools, actions, and procedures, aggregated from several separate sources. The pipeline extracts, prepares, automates, and transforms data – without the need for tedious manual tasks related to extracting, validating, combining, filtering, loading, and transporting the data. This streamlined approach creates a simple flow between the data source and the target destination, saving lots of time and effort for data teams. It minimizes errors and bottlenecks, improves efficiency at scale, and meets today’s demanding requirements of today's data integration tools.
Clean Data Wanted
Enterprises need a constant supply of fresh, reliable, high-quality data to (1) assemble a complete customer profile, based on a Customer 360 platform, and (2) drive business outcomes, based on an operational intelligence platform. Both are difficult to attain, but together, they form one of the most significant objectives for data-intensive enterprises.
Current data processes and results remind us that there’s still a long way to go before reaching our data goals. We're witnessing some of the world’s most advanced companies invest countless resources in building and maintaining data lakes and data warehouses, yet unable to turn their data into actionable business insights. Research shows that 85% of big data projects still fail, and 87% of data science tasks never even make it to production.
Automation Needed
These results are disturbing. but understandable when data scientists spend around 80% of their precious time on building data pipelines and then tracking, mapping, cleansing, and organizing data. That means that only 20% of their busy schedules can be devoted to analysis and other meaningful tasks designed to move the organization forward. This “data disaster” leaves entire industries behind.
If you were to ask data scientists or data analysts the question, “What is a data pipeline?”, their answer might be, "A single, end-to-end solution that locates, collects, and prepares the required data, resulting in ready-to-use datasets." Data teams can no longer rely on partial solutions, that don't include data governance tools, and that can't handle massive volumes of data, or be be automated.
Data Pipeline Challenges
In building data pipelines, enterprises want to know what would work best for them. Finding the right tools isn’t easy, due to some formidable challenges, including:
-
Scale and speed
More data is generated today than ever before, and the massive amounts of data that companies and individuals create grow exponentially year after year. In 2020, we generated more data than expected and set a new record due to the digitization of the Covid-19 pandemic. Enterprises need pipeline solutions that can handle data at this volume and deliver the data quickly and continuously to any target system.
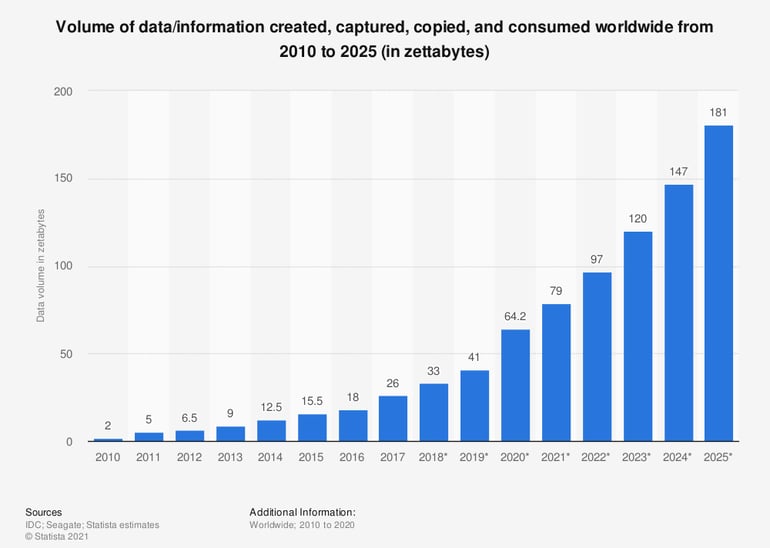
Source: Statista
Data pipelining solutions must be able to accommodate more data, and more data stores.
-
Data fragmentation
Around 90% of today’s generated data is unstructured, with 95% of companies stating that managing fragmented data is their biggest business problem. An organization’s data capabilities are only as strong as its ability to aggregate, manage, and direct data on time. Considering the multiple resources and scale challenges we’ve mentioned, this obstacle is hard to overcome.
-
Automation and productization
Enterprises may want to develop their own data pipeline solutions, or choose platforms that can be independently customized to fit their needs, which, in theory, isn’t a bad idea. The main problem is that these technologies often lack sufficient automation capabilities, sending teams back to square one and the time-consuming, exhausting checklist of manual duties.
Finding the Right Data Pipeline Solution
The ultimate data pipeline platform should be capable of delivering fresh, trusted data, from all sources, to all targets, at enterprise scale. It must also be able to integrate, transform, cleanse, enrich, mask, and deliver data, however and whenever needed. The end result is not only clean, complete, and up-to-date data, but also automated data orchestration flows that can be used by data consumers.
 An Enterprise Data Pipeline, in a Data Product Platform, is fully automated, from ingestion to consumption.
An Enterprise Data Pipeline, in a Data Product Platform, is fully automated, from ingestion to consumption.
Unlike traditional ETL and ELT tools, that rely on complex and compute-heavy transformations to deliver clean data into lakes and DWHs, data pipelining, in a Data Product Platform, moves business entity data via Micro-Databases™, at massive scale, ensuring data integrity and high-speed delivery.
The platform lets you auto-discover and quickly modify the schema of a business entity (such as a customer, product, place, or means of payment). Data engineers then use a no-code platform to integrate, cleanse, enrich, mask, transform, and deliver data by integrating entities – thus enabling quick data lake queries, without complicated joins between tables. And since data is continually collected and processed by Micro-Database, it can also be delivered to operational systems in real time, to support Customer 360 solution, operational intelligence, and other use cases.





