











Table of contents
Are data lakes and/or warehouses the best platforms for integrating structured data into retrieval-augmented generation architectures? Let’s find out.
For RAG, structured data is a must
The need for real-time access to structured enterprise data for generative AI has become clear. Now, many companies are turning to Retrieval-Augmented Generation (RAG) to make it happen, with data lakes and/or data warehouses serving as the data foundation.
What this approach essentially means, is that instead of direct access to the operational systems, the LLM's agents and related functions access the data that resides in the data lake, as per the illustration below.

While offering significant advantages to RAG on structured data, data lakes also present challenges worth considering. Let’s examine the benefits and potential pitfalls of integrating data lakes into your RAG implementations.
Benefits of using data lakes for RAG
Data lakes, which serve as the data source of RAG for structured data, are:
-
Scalable
Data lakes are engineered to accommodate vast amounts of data. This is essential for RAG GenAI apps, which rely on large datasets to enhance the relevance and precision of their responses. As data volumes and variety increases, data warehouses and lakes can expand horizontally to meet future needs.
-
Accommodates a variety of data types
Data lakes can ingest and store a wide range of data types, including unstructured, structured, and semi-structured. High versatility enables them to integrate data from diverse sources, allowing for a rich and comprehensive knowledge base well suited to a RAG architecture.
-
Adaptable to new data
Data lakes can easily accommodate new data types and sources without requiring significant infrastructure changes. This adaptability makes them ideal for evolving data environments.
-
Cost-effective storage
As generally cost-efficient storage solutions, data lakes offer a budget-friendly way to manage the large datasets RAG conversational AI apps require. As data volumes rise, these cost-saving benefits compound.
-
They're there to use!
Most large organizations have already invested in data lake and/or data warehousing technology, and have implemented the needed ETL/ELT tooling to hydrate them with enterprise data. It would seem an obvious place to source the data needed to ground an LLM.
Despite their advantages, there are also significant limitations in using data lakes for RAG for structured data, including:
1. Complex ETL
While data lakes reduce some ETL (Extract, Transform, Load) costs by allowing raw data ingestion, the transformation process remains crucial for RAG use cases. Ingesting raw data can lead to data quality issues such as inconsistency and redundancy. Maintaining data integrity and ensuring clean, high-quality AI data often requires substantial effort and resources.
2. Performance Issues
Real-time data ingestion is essential for a customer-centric RAG LLM. Although many data warehouses and lakes support real-time data ingestion, it often depends on the source system's streaming capabilities.
Joining across multiple tables with millions or billions of records can be time-consuming, especially for large organizations. Unlike traditional databases, data lakes often lack advanced indexing capabilities, leading to slower data retrieval and processing times for structured data queries.
As a result, executing complex queries could take too long. This means that conversational chatbots, which require immediate response will not be able to satisfy this mandatory requirement.
3. Difficulty handling transactional workloads
Data lakes are not designed for transactional workloads that require quick read-write operations and high consistency. This pitfall becomes even more poignant when considering thousands, or even millions, of users executing queries concurrently.
4. Risk of data exposure
Governing data lakes can be challenging, especially when dealing with sensitive structured data that requires stringent access controls and audit trails. Ensuring robust security measures in a data lake is even more complex because they enable diverse data and access methods.
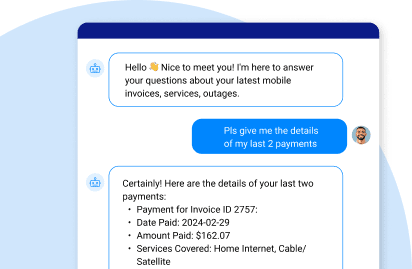
In addition, allowing LLMs unrestricted access to the entire data lake increases the risk of unauthorized information disclosure. For instance, a customer querying their invoices may inadvertently receive information about another customer. Or malicious actors could intentionally request or manipulate the LLM into disclosing another customer’s sensitive data. These security risks highlight the difficulty in ensuring data segregation and privacy.
5. Expensive data management
While storage in data lakes can be cost-effective, managing, processing, and securing complex data can become expensive. Additionally, cloud-based data warehouses and lakes often operate on a pay-per-use model, in which each query incurs charges based on data volume and access frequency. This can lead to unpredictable and potentially high costs.
6. Problems catching up
In the new GenAI reality, anyone can ask any question about the data. Because all the data resides in the data lake, but you can’t really predict the next question, organizations end up building and maintaining thousands of LLM agents and functions, each one addressing a specific domain, drawing extremely high costs for their creation and maintenance.
Optimizing RAG for structured data with K2view
While data lakes are effective for static business intelligence use cases, they often fall short for operational applications that require real-time, personalized, and contextually relevant data, such as RAG-based agents. Their limitations in handling immediate data needs, as well as data governance and security vulnerabilities, make them less suitable for retrieval-augmented generation.
As opposed to “macro” data lakes, K2view GenAI Data Fusion supports a “micro” approach that organizes enterprise data into 360° views of every business entity (e.g. all the data related to a single customer) – making sure you’re always ready for any question, by anyone, while never exposing compromising sensitive data to the LLM.
The K2view Micro-Database is ideally suited for RAG-based applications driven by enterprise data. Being a "data lake of 1", it provides all the benefits of a data lake, while avoiding all the pitfalls that traditional data lakes introduce to RAG-based apps.
Learn more about the premier RAG tool for structured data – GenAI Data Fusion by K2view.
