






A practical guide to Retrieval-Augmented Generation (RAG)
What is RAG (Retrieval Augmented Generation)?
Updated December 10, 2024

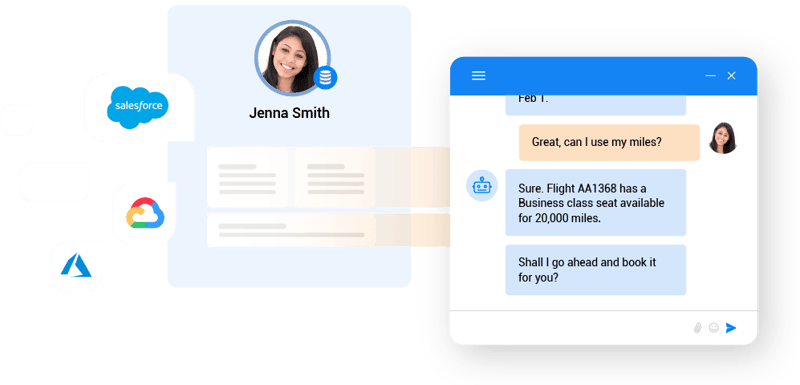

 Table of Contents
Table of Contents

Retrieval-augmented generation challenges
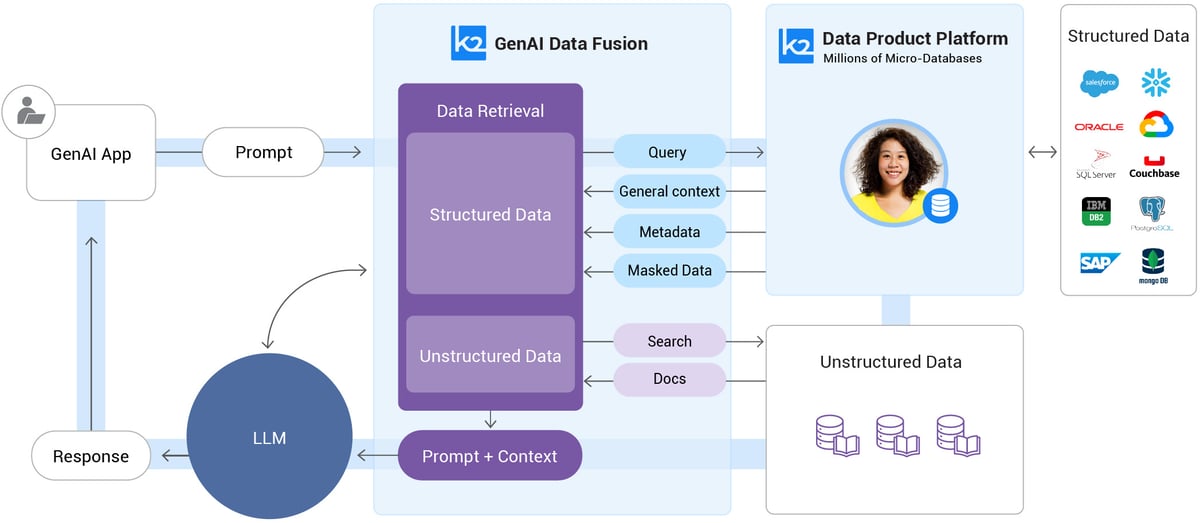
An organization usually stores its documentation of internal processes, procedures, and operations in offline and online docs – with its business data fragmented across dozens of enterprise systems, like billing, CRM, and ERP.
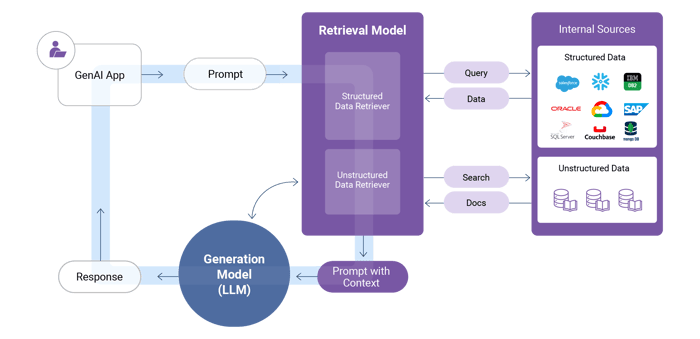
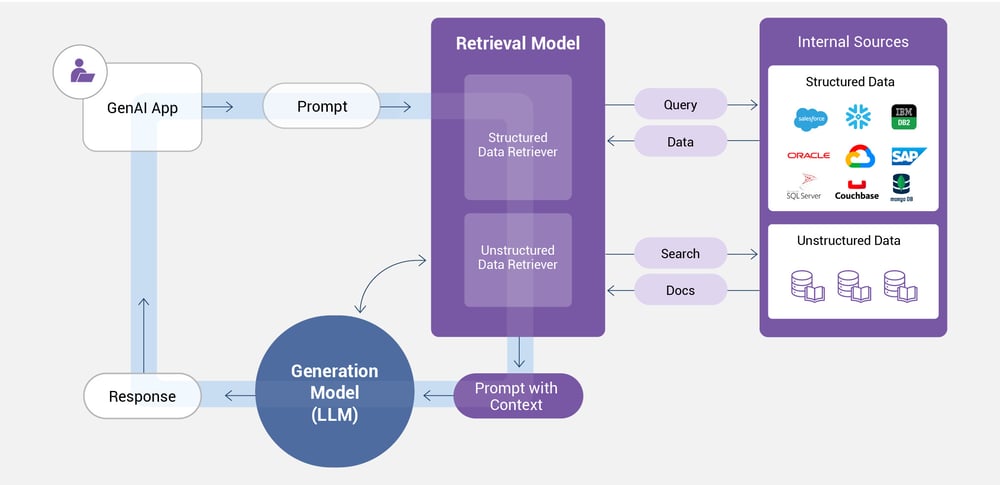
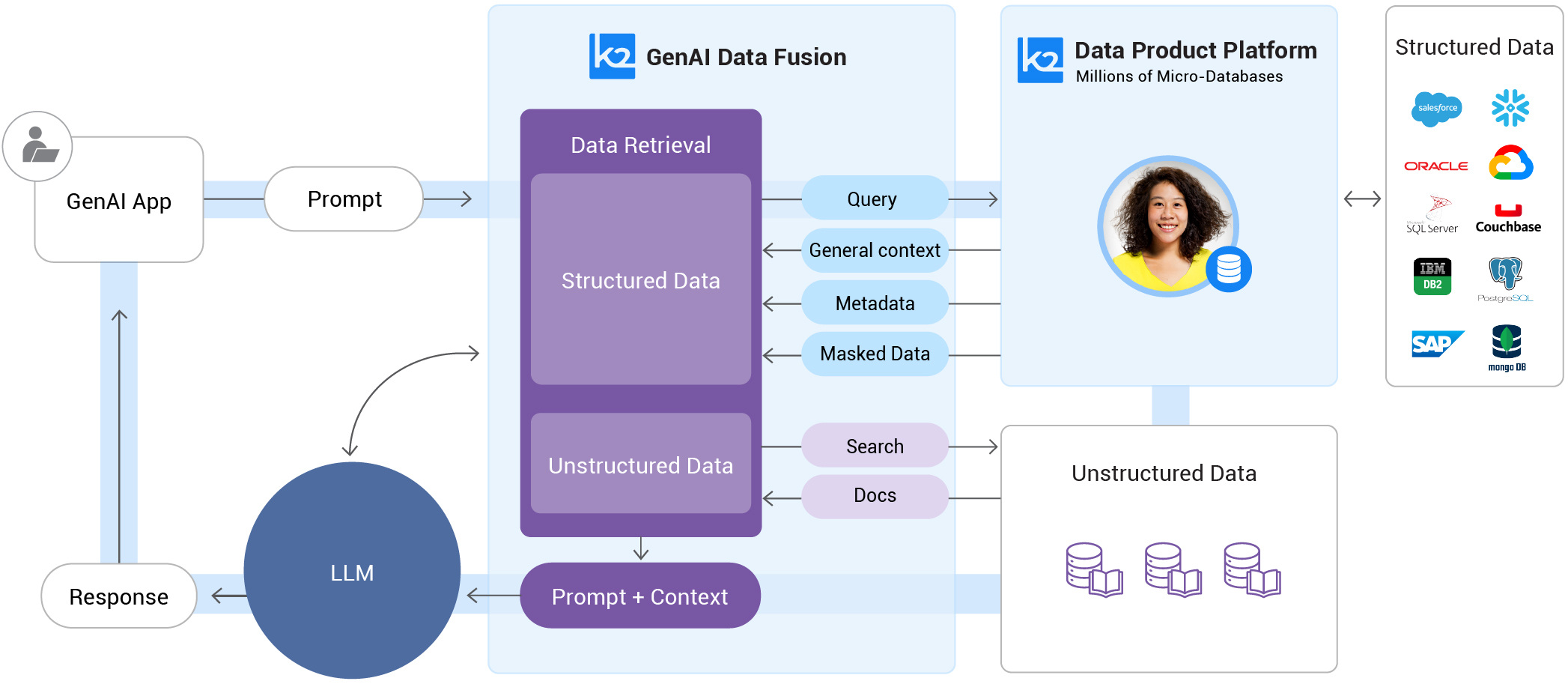
Active retrieval-augmented generation integrates fresh, trusted data retrieved from a company’s internal sources – docs stored in document databases and data stored in enterprise systems – directly into the generation process.
So, instead of relying solely on its public, static, and dated knowledge base, the enterprise LLM actively ingests relevant data from a company’s own sources to generate better-informed and relevant outputs.
The RAG model essentially grounds the LLM with an organization’s most current information and GenAI data, resulting in more accurate, reliable, and relevant responses.
However, RAG also has its challenges:
- Enterprise RAG relies on enterprise-wide data retrieval. Not only must you maintain up-to-date and accurate information and data, you must also have accurate metadata in place that describes your data for the RAG framework.
- The information and data stored in internal knowledge bases and enterprise systems must be of AI data quality: accessible, searchable, and of high quality. For example, if you have 100 million customer records – can you access and integrate all of David Smith’s details in less than a second?
- To generate smart contextual prompts, you’ll need sophisticated prompt engineering capabilities, including chain-of-thought prompting, to inject the relevant data into the RAG LLM in a way that generates the most accurate responses.
- To ensure your data remains private and secure, you must limit your LLM’s access to authorized data only – per the example above, that means only David Smith’s data and nobody else’s.
Besides these challenges, organizations have additional concerns, as revealed in our recent survey:

Top concerns in leveraging enterprise data for GenAI and RAG
Source: K2view Enterprise Data Readiness for GenAI in 2024 report
With the top concerns so evenly spread, it’s obvious that addressing only one issue, such as scalability and performance, without ensuring data quality and consistency, real-time data integration and access, data governance and compliance, or data security and privacy, is insufficient. A completely holistic approach is needed to effectively integrate enterprise data with GenAI projects.
According to the 2024 Gartner LLM report, Lessons from Generative AI Early Adopters, "Organizations continue to invest significantly in GenAI, but are challenged by obstacles related to technical implementation, costs, and talent."
Despite these challenges, RAG still represents a great leap forward in generative AI. Its ability to leverage up-to-date internal data addresses the limitations of traditional generative models by improving the user experience with more personalized and reliable exchanges of information.
RAG AI is already delivering value in several domains, including customer service, IT service management, sales and marketing, and legal and compliance. Still, depending on the use case, RAG vs fine-tuning vs prompt engineering is under constant evaluation.
Experience agentic AI
Go behind the scenes and see the process of grounding AI agents with enterprise data





-1.png?width=501&height=273&name=GenAI%20survey%20news%20thumbnail%20(1)-1.png)



