











Table of contents
Learn how to prepare for RAG with this FREE condensed version of the 2024 Gartner LLM report, “How to Supplement Large Language Models with Internal Data”.
Gartner LLM report on preparing for RAG
Enterprises that can leverage Large Language Models (LLMs) effectively are likely to be more operationally efficient and commercially competitive.
Retrieval-Augmented Generation (RAG) is a design pattern that augments an enterprise LLM with fresh, trusted data retrieved from authoritative internal knowledge bases and enterprise systems, to generate more informed and reliable responses.
According to a 2024 Gartner report entitled, “How to Supplement Large Language Models with Internal Data”, enterprises can prepare themselves for RAG implementations by taking several considerations into account, listed as Gartner LLM tips in this article.
Learn more about grounding enterprise LLMs with RAG
in the complete guide to retrieval-augmented generation.
Gartner LLM tip 1: Focus your scope
Large language models can:
-
Write copy.
-
Use different tones of voice.
-
Translate text into instructions, queries, or different languages.
RAG enables enterprises to access their own private, internal, up-to-date data and adjust the LLM prompts for greater accuracy, context, and relevancy. Designed to deliver business value, LLM grounding via RAG can:
-
Integrate updated or real-time information.
-
Identify the knowledge source.
-
Rank the responses for relevancy.
-
Enhance output accuracy and coherence.
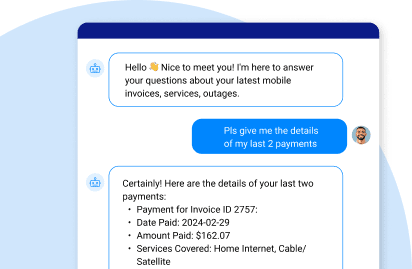
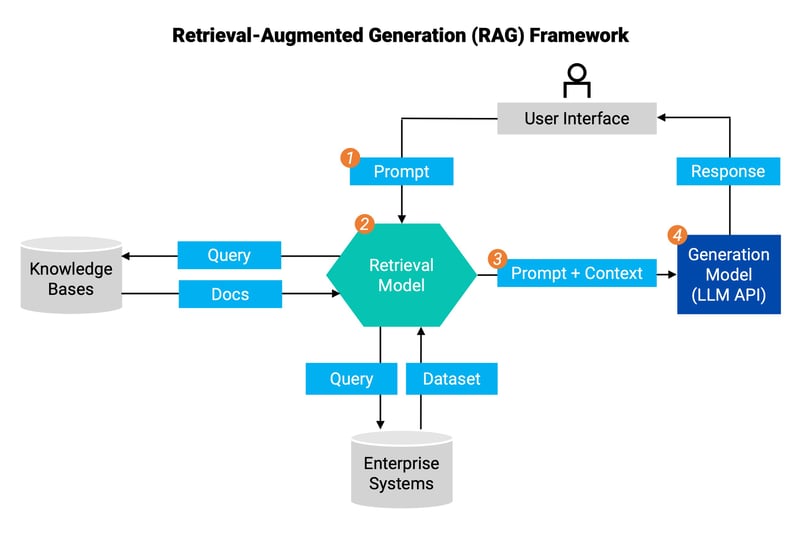 Inspired by Gartner, this diagram illustrates the retrieval-augmented generation framework:
Inspired by Gartner, this diagram illustrates the retrieval-augmented generation framework:
- The user (at the top) prompts the retrieval model.
- The retrieval model queries the company's internal sources (knowledge bases and enterprise systems) for the most relevant docs and dataset.
- The retrieval model augments the user's original prompt with additional contextual information and passes it on as input to the generation model (LLM API).
- The LLM uses the augmented prompt to generate a more informed response and then sends it back to the user.
Gartner LLM tip 2: Select your use case
Enterprise LLM-RAG use cases can span multiple enterprise domains, as shown in the following table:
|
Department |
Objective |
Types of RAG data |
|
Customer service |
Personalize the chatbot experience to each customer to respond more effectively. |
|
|
Sales and marketing |
Engage with potential customers on a website or via chatbot to describe products and offer recommendations. |
|
|
Legal and compliance |
Draft and summarize legal documents and create compliance policies and training materials. |
|
|
HR |
Generate interview questions, job descriptions, employment agreements, survey results, and suggestions for company activities and events. |
|
Gartner LLM tip 3: Classify your data
Data is generally classified as structured, semi-structured, or unstructured. The distinction is critical to your LLM-RAG initiative because it helps you determine the database technologies, security features, storage needs, query methods, processing, and architectural considerations best suited to your needs.
Start by identifying and classifying your underlying data, as shown in this sample data taxonomy diagram.
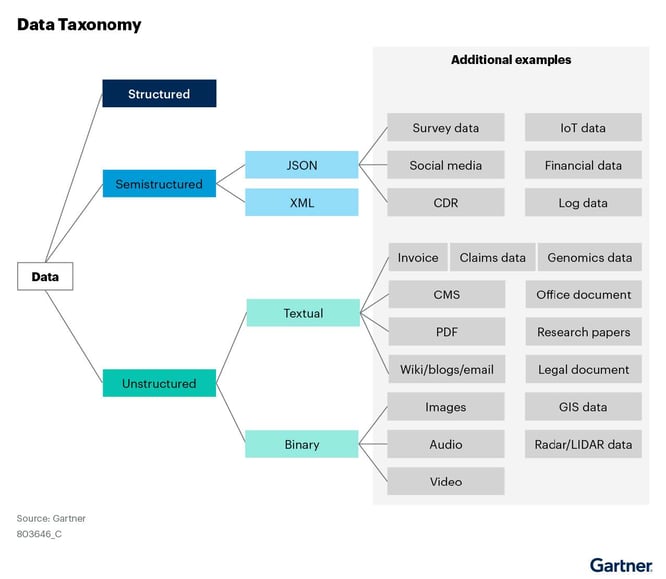
Some of your most valuable insights might be hidden in unstructured textual data, typically in the form of PDFs and other file types.
| For your first RAG pilot, make sure your: | Note that unstructured data: |
| Use case involves your internal data | Has no set format |
| Internal data is in a text format | Can’t be defined by an AI database schema generator |
Gartner LLM tip 4: Make your data RAG-friendly
As discussed in the previous section, RAG enables unstructured data to be identified, interpreted, and applied with the right context. But you’ll need to parse, extract, or chunk the data, convert it to embeddings, and then safely store those embeddings for retrieval when prompted.
For RAG data readiness, make sure your unstructured data files can:
-
Support text extraction
-
Be stored in a normal or vector search engine
Then answer the following questions:
| Data | Data sources |
| Do you know who produced the data and where it’s from? | What’s in these documents? |
| Is the data producer trustworthy? | When were they created? |
| Can you contact the data producer for support? | How much data can be extracted from these documents? |
| Is there metadata about the data? | How easily can this data be organized for your AI data use cases? |
| If so, is it reliable, consistent, complete, and up to date? | Are there other data sources you could use? |
Gartner LLM tip 5: Choose your technology
Knowledge graphs and vector databases are both technologies that enable RAG and can be used alone or together.
Knowledge graphs
Knowledge graphs interpret and understand existing information, relationships in a domain, and rules that connect one entity to another semantically. Knowledge graphs can extract metadata embedded in image files, documents, and PDFs. This capability allows for search and query of file formats, creation/modification dates, authors, keywords, and titles.
Vector databases
Vector databases enable enterprises to retrieve data based on its meaning or context, and then to use that data to augment RAG prompt engineering. Built to process unstructured data at scale, they improve the quality and relevance of the resulting generated outputs.
RAG via generative data products
Generative data products are reusable data assets generated by AI that combine data with everything needed to make them clean, compliant, current, and easily accessible by authorized users. They power enterprise RAG use cases via insights derived from your organization’s internal data and information.
Generative data products retrieve fresh, trusted internal data into the RAG framework in real time, to:
-
Integrate the customer 360 or product 360 data from all relevant data sources.
-
Translate data and context into relevant prompts.
-
Feed it to the LLM along with the user’s query.
The LLM then delivers an accurate and personalized response to the user (via a RAG chatbot, for example).
Generative data products can be accessed via API, CDC, messaging, streaming – in any combination – to unify data from multiple source systems.
RAG is useful for many use cases, such as:
| Accelerating issue resolution | Creating hyper-personalized marketing campaigns | Generating personalized cross-/up-sell recommendations for call center agents | Detecting fraud by identifying suspicious activity before damage can be done |
Discover K2view GenAI Data Fusion, the RAG tools that tip the scale in your favor.
