




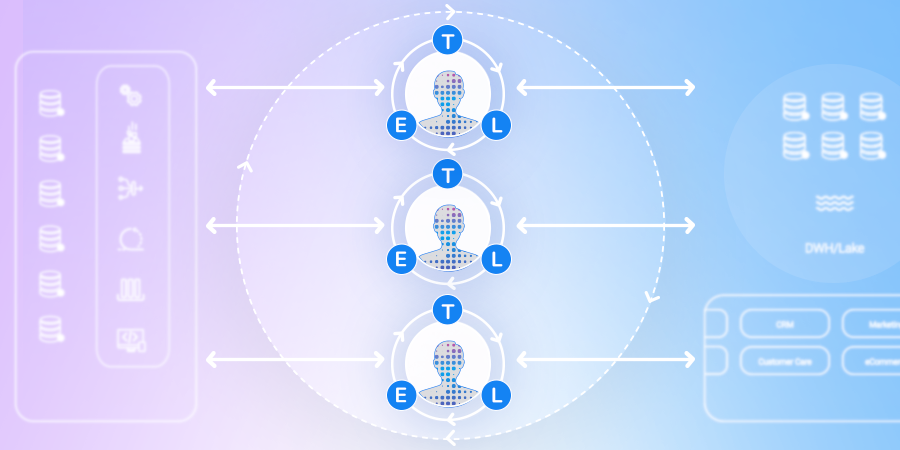
Enterprises are increasingly moving from complex and expensive data pipelines, based on on ETL or ELT, to smart, agile data pipelines that are based on business entities – "entity-based ETL" (eETL).
This paper examines ETL versus ELT, and discusses the logical evolution to eETL, along with its benefits.
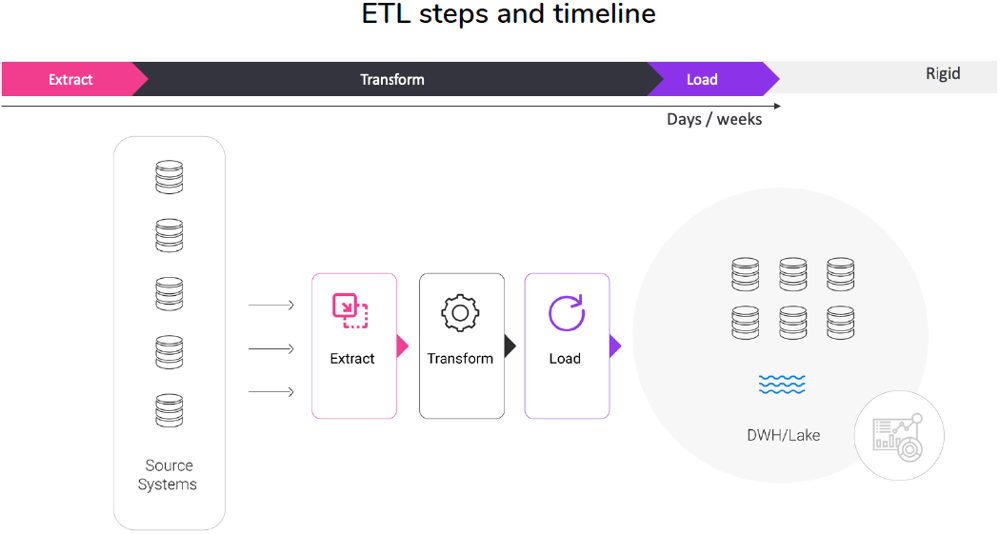
The traditional approach to data integration, known as extract-transform-load (ETL), has been around since the 1970s. In the ETL process, data is extracted in bulk from various sources, transformed into a desired format, then loaded for storage into its target destination.
ETL workflow
| Extract | Transform | Load |
| Raw data is read and collected from various sources, including message queues, databases, flat files, spreadsheets, data streams, and event streams. | Business rules are applied to clean the data, enrich it, anonymize it, if necessary, and format it for analysis. | The transformed data is loaded into a big data store, such as a data warehouse, data lake, or non-relational database. |
Traditional ETL has the following disadvantages:
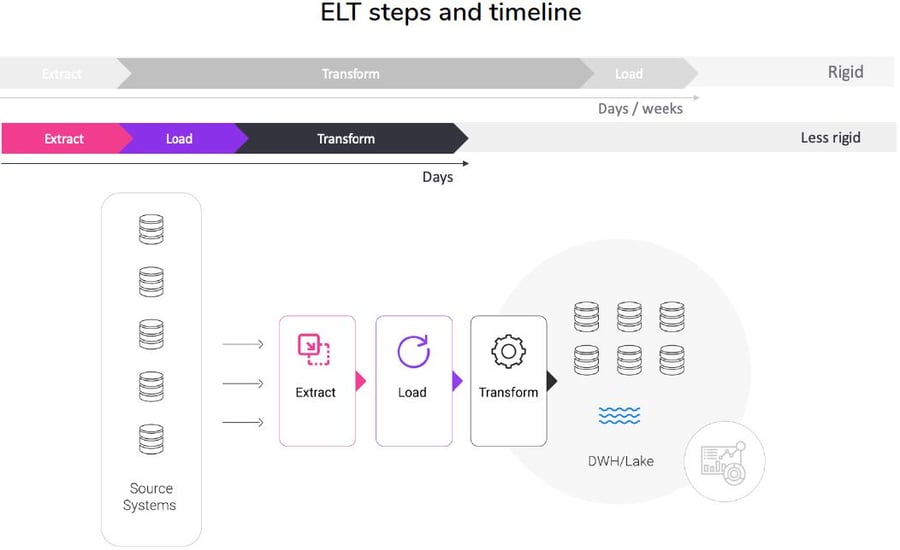
ELT stands for Extract-Load-Transform. Unlike traditional ETL, ELT extracts and loads the data into the target first, where it runs transformations, often using proprietary scripting. The target is most commonly a data lake, or big data store, such as Teradata, Spark, or Hadoop.
ELT workflow
| Extract | Load | Transform |
| Raw data is read and collected from various sources, including message queues, databases, flat files, spreadsheets, data streams, and event streams. | The extracted data is loaded into a data store, whether it is a data lake or warehouse, or non-relational database. | Data transformations are performed in the data lake or warehouse, primarily using scripts. |
ELT has several advantages over ETL, such as:
While the ability to transform data in the data store answers ELT’s volume and scale limitations, it does not address the issue of data transformation, which can be very costly and time-consuming. Data scientists, who are high-value company resources, need to match, clean, and transform the data – accounting for 40% of their time – before even getting into any analytics.
ELT is not without its challenges:
The following table summarizes the main differences between ETL vs ELT:
| ETL | ELT | ||
| Process |
|
|
|
| Primary Use |
|
|
|
| Time to insights |
|
|
|
| Compliance |
|
|
|
| Technology |
|
|
|
| Cost |
|
|

An innovative new approach addresses the limitations of both traditional ETL and ELT, and delivers trusted, clean, and complete data that can immediately be used to generate insights.
eETL steps and timeline
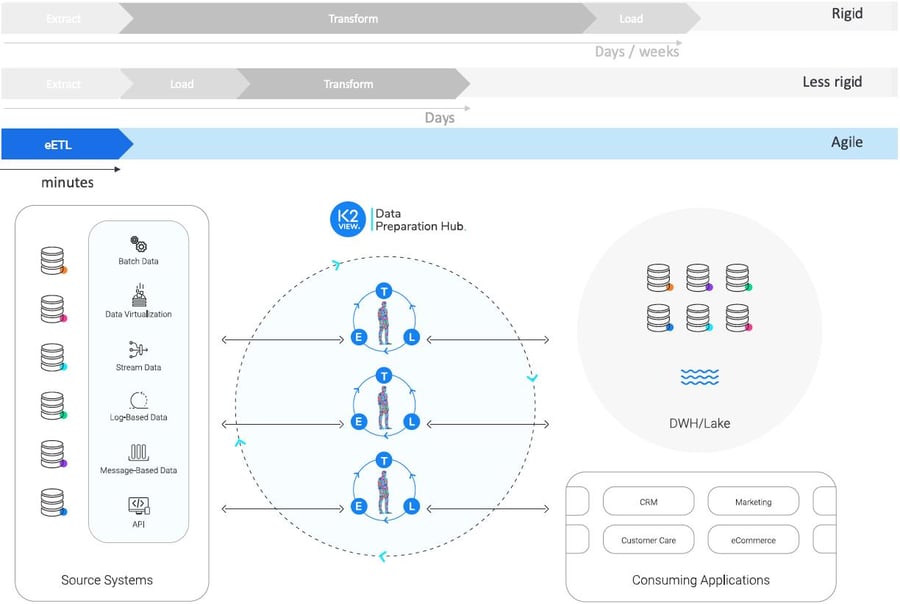
At the foundation of the eETL approach is a logical abstraction layer that captures all the attributes of any given business entity (such as a customer, product or order), from all source systems. Accordingly, data is collected, processed, and delivered per business entity (instance) as a complete, clean, and connected data asset.
In the extract phase, the data for a particular entity is collected from all source systems. In the transform phase, the data is cleansed, enriched, anonymized, and transformed – as an entity – according to predefined rules. In the load phase, the entity data is safely delivered to any big data store.
eETL represents the best of both (ETL and ELT) worlds, because the data in the target store is:
The table below summarizes the ETL vs ELT vs eETL approaches to big data preparation:
| ETL | ELT | eETL | |
| Process |
|
|
|
| Primary Use |
|
|
|
| Flexibility |
|
|
|
| Time to insights |
|
|
|
| Compliance |
|
|
|
| Technology |
|
|
|
| Cost |
|
|
|
As explained above in the ETL vs ELT comparison, each method has its own advantages and disadvantages. Applying an entity-based approach to data pipelining enables you to overcome the limitations of both approaches and deliver clean and ready-to-use data, at high scale, without having to compromise on flexibility, data security, and privacy compliance requirements.

Download the whitepaper to compare ETL, ELT and entity-based ETL pipelining of data from any source to any lake or DWH.
Overcomes the disadvantages of ETL and ELT
Continuously delivers complete, clean, and timely data – at any scale
Automates and productizes the data preparation process
Supports both analytical and operational workloads

