








The top technology trend for 2022 is Data Fabric. A successful Data Fabric architecture is based on Data Products. Make the connection by reading this article.
Table of Contents
Why We Should Care about Business-Critical Technology Trends
Why Data Fabric is the #1 Gartner Technology Trend for 2022
Data Fabric – Machine Learning Inside
Data Fabric Based on Data Products
Vodafone Customer Testimonial
4x the Outcomes in 2 Years
Why We Should Care about Business-Critical Technology Trends
Each year, analyst firm, Gartner, picks the top technology trends most critical to business. For 2022, it lists 12 strategic trends it believes will enable enterprises to deliver digitalization, efficiency, and growth – while positioning IT as a strategic partner in the organization.
“CEOs know they must accelerate the adoption of digital business and are seeking more direct digital routes to connect with their customers,” says David Groombridge, VP Analyst, Gartner. “But with an eye on future economic risks, they also want to be efficient and protect margins and cash flow.”
Why Data Fabric is the #1 Gartner Technology Trend for 2022
Gartner places Data Fabric under its “Trust” category, along with other trends it considers to be foundational to IT. The technologies in this segment were designed to ensure that data is integrated and processed more securely, across cloud and non-cloud environments, to deliver greater cost-efficiencies at scale. (Besides “Trust”, Gartner defined 2 other categories: “Change” and “Growth”.)
Data Fabric was chosen as the #1 Gartner Technology Trend for 2022 because it:
-
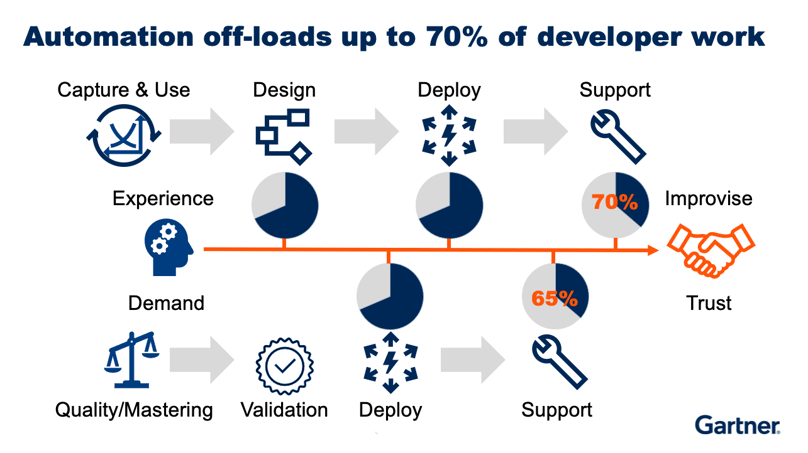
Recovers up to 70% of developer work, in data discovery, analysis, and implementation tasks. It also includes additional data management tools, as they emerge, in an evolutionary and prioritized way, in order to avoid “rip and replace” practices.
 Once data teams experience a Data Fabric that knows what it doesn’t know, trust is established.
Once data teams experience a Data Fabric that knows what it doesn’t know, trust is established.
-
Enables any amount of data users, from the reuse of data assets, for operational and analytical use cases, to the quick ingestion of data, from internal systems, public domains, and business partners.
-
Allows staff to provide more benefits, from more data, by accelerating the introduction, and exploitation, of 2nd and 3rd-party data. In comparison, traditional methods require a lot of manual integration, before the data can bring any value.
Data Fabric – Machine Learning Inside
Data Fabric automates data integration, data preparation, and orchestrates its delivery. It combines multiple data integration methods into a single platform: ETL (bulk), messaging, streaming, CDC, APIs, and data virtualization.
Data fabric becomes a trusted data management partner over time, by first observing, and then learning, human behavior. For enterprises, it can cut the time to design, deploy, and support data, in half.
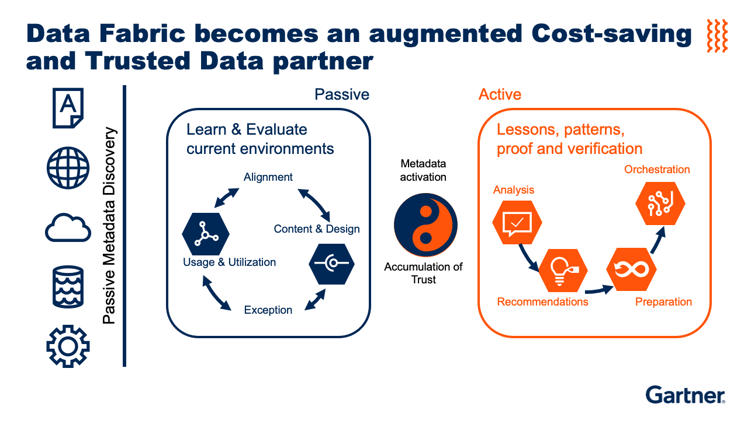
A Data Fabric is more than just a high-speed, high-scale data integration tool. It can apply machine learning to “learn” the data (including static and active metadata), and then recommend data structures on the fly. This ML capability can be broken down into 3 stages:
-
Passive learning
Data Fabric learns what data exists and applies AI to add any metadata that’s missing. -
Behavior analysis
Data Fabric uses metadata to learn where, and how, data is being used. It then analyzes other data for similar behavior. If the behavior is the same, it’s probably already usable. -
Active recommendations
Data Fabric relies on active metadata (e.g., performance, usage, etc.) in order to generate recommendations to data engineers. For example, it can advise on the type of data – e.g., new data, more data, or best data – to deliver to data consumers.
 Data Fabric gains the confidence of data teams over time.
Data Fabric gains the confidence of data teams over time.
Data Fabric Based on Data Products
A data product approach to Data Fabric represents its most advanced form. In contrast to data mesh, where every business domain can define, access, and control its own data products, data fabric takes a more centralized approach, leveraging ML to automate data product discovery, creation, and ongoing adaptation.
A data product answers the needs of one or more data consumers. It typically relates to a specific business entity (e.g., a customer, product, order, etc.), allowing data consumers to easily access complete, clean data for operational and analytical workloads – whenever and wherever they need it, irrespective of the data’s origins.
The data inside a data product typically originates in dozens of fragmented source systems, and is usually of different formats, structures, technologies, and terminologies.
A data product unifies everything a company knows about a particular business entity, including its interactions, transactions, and master data – and whether the data is structured or not – and provides central data governance measures.
Data products are so relevant to Data Fabric, because they are:
-
Created from source data, found in existing systems (where each instance of a data product has its own data, managed as a holistic unit)
-
Continually syncing, with their respective source systems
-
Defined by metadata, including access controls, data processing logic, integration methods, masking techniques, schema, and more
-
Easily accessed by authorized data consumers, in a variety of data delivery methods
-
Enriched with situational awareness, in real time, or derived from offline analytics and/or ML algorithms
Gartner, in listing Data Fabric as one of the top technology trends, cites the need to drive both operational and analytical use cases. A data product approach to Data Fabric enables a wide variety of workloads, including:
Customer Testimonial
See how Vodafone uses Data Fabric to enable strategic business outcomes across the company.

4x the Outcomes in 2 Years
Ultimately the reason why Gartner lists its top technology trends each year, is to lead to better business outcomes, and to establish IT as an important contributor to the enterprise. Data Fabric was selected as THE top technology trend for 2022 because it shows great potential.
According to a recent Gartner Strategic Planning Assumption (analysis by Mark Beyer et al):
“By 2024, Data Fabric deployments quadruple data utilization outcomes by cutting human-driven data management tasks in half.”





