







With the rising need for self-service data integration, enterprises require a more effective cloud data pipeline solution. iPaaS, based on data products, is the answer.
The Data Pipeline Imperative
Data is the leading currency in business today. But without the ability to easily integrate, transform, query, and analyze that data, it’s impossible to reap its full value.
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are the standard data integration processes businesses rely on to move raw data from source systems to a target database, such as a data warehouse or data lake.
However, these data pipeline tools are ill-equipped to meet the demanding needs of today’s enterprises. The rise of cloud computing, the growing need for self-service data integration, and the ever-increasing volume of data sources and formats are driving enterprises to adopt a cloud data pipeline solution.
In this article we examine the cloud data pipeline, the flaws inherent in ETL and ELT processing, and how a real-time data product approach gives enterprises significant advantages.
What's a Data Pipeline?
A data pipeline is a set of actions and processes that ingests, prepares, transforms, masks, and moves raw data, from diverse source systems, and delivers it to a target data store, such as a data lake, a data warehouse, or an operational system for storage, processing, and analysis. It can make use of various data integration methods, including ETL, ELT, APIs, streaming, messaging, CDC, and data virtualization.
With companies continuously implementing more software and apps to their tech stack, data pipelines enable organizations to manage data integrations and workloads more efficiently, improve data quality, and meet data governance standards.
What's a Cloud Data Pipeline?
The term “cloud data pipeline” refers to a data pipeline architecture that moves and integrates data, from both on-premise and cloud source systems, to any target data store, using a cloud-based data integration platform.
Today, the majority of enterprises have adopted multi-cloud and hybrid cloud strategies. Cloud data pipelines enable organizations to integrate dozens of data sources, spanning multiple technologies and different data structures.
In the current business landscape, business users need data to make smarter decisions and stay competitive. However, harnessing timely insights from a growing number of disparate data sources is a persistent challenge.
Cloud data pipelines allow you to serve all existing and future data integration needs, using a simplified and unified solution on the cloud. They support the growing need for a self-service approach to data, empowering business users to gain a robust view of customers, improve operational efficiency, and drive better business outcomes.

Timely insights lead to better customer experiences and business outcomes.
Understanding the Weaknesses of ETL and ELT
ETL and ELT data pipelines represent the 2 traditional approaches to data pipelining. Both approaches include the same 3 steps. The difference is the order in which they are performed. The 3 steps are:
-
Extract: This step always comes first. It involves pulling structured and unstructured data from all of your source systems, including SaaS, websites, on-premise, and more. After the data is extracted, it is moved into the staging area.
-
Transform: In this step, the data is cleaned, processed, and transformed into a common format, so that it can be consumed by the target destination (e.g., data warehouse, data lake, or database).
-
Load: This step involves loading the formatted data into the target system. From there, the data is ready to be analyzed.
ETL
ETL (Extract, Transform, Load) has been the standard approach to gathering, reforming, and integrating data for decades. Today, businesses that need to synchronize different data environments and migrate data from legacy systems, use ETL pipelines.
Since it transforms data before loading it to the target system, ETL helps reduce the volume of data that is stored. It can also mask, delete, and encrypt specific data to enable companies to comply with data privacy regulations, such as GDPR and CCPA.
However, ETL has some major disadvantages.
Traditional ETL pipelines are incredibly slow, and consume heavy computing resources. Often, it’s necessary to wait for all transformations to be complete before loading the data into the destination. They’re also not very flexible, and require continuous maintenance. For example, if your input sources and formats change, you need to configure these transformations, and edge cases, in advance. Finally, defining business logic and transformations for your ETL process usually comes at a high price.
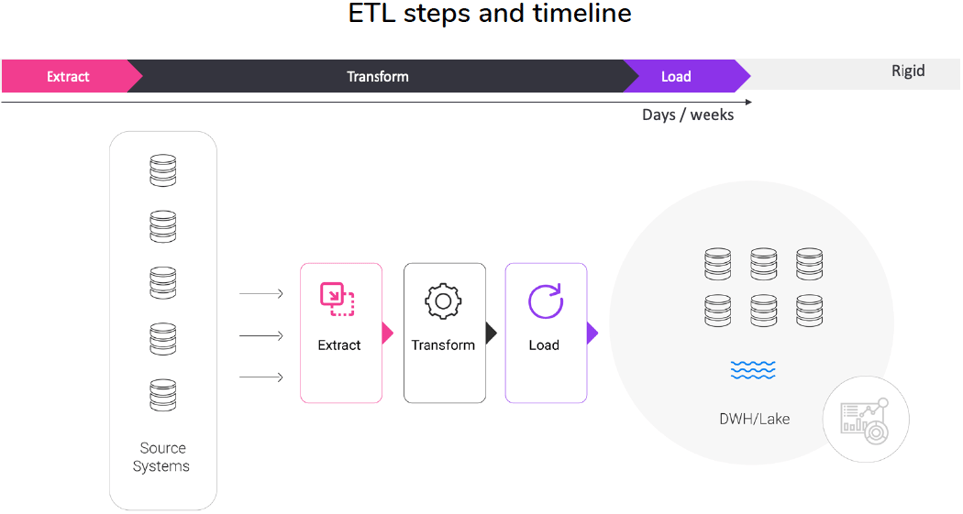
ETL pipelines are inflexible, maintenance-heavy, and take days/weeks to complete.
ELT
ELT (Extract, Load, Transform) is a newer, more popular approach to data pipelining. It swaps the second and third steps in the integration process, so that the data is only transformed after it is loaded onto the target system.
The rise of ELT is due to the ubiquity of cloud storage. Today, enterprises can powerfully and affordably store massive amounts of data in the cloud. As a result, it is far less important to filter data, and reduce data volumes, before transferring it to target systems. The other main reason ELT is more desirable, is because ETL pipelines are not suited to process the rising volume of unstructured data generated by cloud-based systems.
Unlike ETL, the ELT pipeline process is fast, flexible, and allows for easy integration of new or different data sources into the data pipeline. Since ELT is more automated, it requires minimal maintenance. It’s also highly scalable, and costs much less than ETL.
However, ELT also has its own disadvantages.
First, there is still a need to transform the data, once it’s moved onto the data lake, or any other target data store. Transformation can be costly, since data lake and warehouse vendors charge customers for processing data on the system. Moreover, the effort required to transform, clean, and prepare the data has shifted from the data engineer, to the business data user or data scientist, creating additional time-consuming workloads, and increased latency.
Second, loading all data to target systems before it’s transformed, gives access to various users and applications – creating significant security risks, and making it harder to comply with data privacy regulations.
Why a Data Product Approach is Best for Enterprises
Fortunately, there’s another solution enterprises can use to serve their cloud data pipeline needs.
Instead of ETL and ELT pipeline tools, which rely on complex and compute-heavy transformations, to deliver clean data to target systems, an integration solution that transfers data as data products allows organizations to build a scalable data pipeline infrastructure with minimal effort.
A data product approach asserts that each business domain in an enterprise should be able to define, access, and control its own data. A Data Product Platform extracts and processes all the data related to a given business entity – such as a customer, vendor, order, or claim – and makes it instantly accessible to authorized data consumers. It integrates, unifies, and tokenizes data from underlying source systems, and delivers the business entity dataset to business users.
Data products are deployed on the cloud as an iPaaS (integration Platform as a Service) using various architectures, such as data mesh and data fabric.
Here’s what a cloud data pipeline based on data products can do:
-
Collect, process, and serve enterprise data, by business entity
-
Ingest and unify data from all source systems, while ensuring data integrity
-
Discover and visualize data lineage, thanks to a built-in data catalog
-
Transform, clean, enrich, and mask data, with reusable functions
-
Encrypt data from source systems, until it is served to the target system
-
Automate and productize data preparation and delivery flows
-
Deliver data to target systems in real-time, according to a schedule, or on demand
6 Benefits of Data Products
When data is organized and managed according to business entities – as opposed to source systems – it’s far easier to define, configure, prepare, monitor, deliver, and adapt.

Data stored as individual business entities can be accessed and used in real time.
Below are the key benefits of using data products to fulfill your cloud data pipeline needs.
-
Easy to create and maintain
Quickly design, engineer, and continually adapt data products with a Data Product Platform. -
Trusted, current insights
Enterprise data is always clean, compatible, and up-to-date. -
Time-based insights
You’ll always know what data has changed, and when the change took place. -
Democratized data analysis: Data products empower authorized business users to easily access and understand data.
-
Always compliant
Data is governed according to centralized or domain-specific policies and regulations. -
Secure and fast
Data is encrypted and compressed, and source systems are never impacted.
Performance Rules with a Cloud Data Pipeline Based on Data Products
Enterprises need a cloud data pipeline solution that lets them integrate their data quickly and effectively, without compromising on speed or security. As discussed, traditional approaches to transferring raw data are not equipped to meet this need.
iPaaS solutions based on data products, enable business users to pipeline fresh, trusted data, from all on-premise and cloud-based systems, to all targets, at scale. They ensures data integrity, high-speed pipelines, and flexibility. And, by enabling business users to access business entity data in real time, data products empower organizations to become more agile in response to shifting business needs.





